
独家对话姚顺宇:请允许我小疯一下
独家对话姚顺宇:请允许我小疯一下他人生最大的一次跨步是博士毕业,毅然决然离开深造9年的物理,来到崭新的AI行业。过去两年,他先后在Anthropic和Google DeepMind出任研究科学家,参与了Claude 3.7、4.5、Gemini 3等关键模型的开发过程。
来自主题: AI资讯
12671 点击 2026-05-11 12:03
 搜索
搜索
他人生最大的一次跨步是博士毕业,毅然决然离开深造9年的物理,来到崭新的AI行业。过去两年,他先后在Anthropic和Google DeepMind出任研究科学家,参与了Claude 3.7、4.5、Gemini 3等关键模型的开发过程。

OpenAI的最新研究揭示了一个反直觉的真相:越强大的推理模型,越管不住自己的「脑子」。在CoT-Control套件测试的13款前沿模型中,DeepSeek R1控制自身思维链的成功率仅为0.1%,Claude Sonnet 4.5也只有2.7%。
英伟达护城河要守不住了?Claude Code半小时编程,直接把CUDA后端迁移到AMD ROCm上了。 一夜之间,CUDA护城河被AI终结了? 这几天,一位开发者johnnytshi在Reddit上分享了一个令人震惊的操作:

目前已经出现了一些早期迹象,通用LLM助手领域的市场格局,正朝着“赢家通吃”,至少是“赢家通吃大部分市场”的趋势发展。在ChatGPT、Gemini、Claude 3和Cursor这几款产品中,仅有9%的用户会为一款以上的产品付费。

o1从榜首暴跌至#56,Claude 3 Opus坠入#139。LMSYS榜单揭示残酷真相:大模型的「霸主保质期」只有35天!这不是技术迭代,这是对所有应用层开发者的降维屠杀。

宾夕法尼亚大学沃顿商学院(The Wharton School)今年发布了一系列名为《Prompting Science Reports》的重磅研究报告。他们选取了2024-2025最常用的模型(如GPT-4o, Claude 3.5 Sonnet, Gemini Pro/Flash等),在极高难度的博士级基准测试(GPQA Diamond)上进行了数万次的严谨测试。

全球首个可大规模落地的开源原生多模态架构(Native VLM),名曰NEO。要知道,此前主流的多模态大模型,例如我们熟悉的GPT-4V、Claude 3.5等,它们的底层逻辑本质上其实玩的就是拼接。
生成式AI技术的成熟,让智能编程逐渐成为众多开发者的日常,然而一个大模型API选型的“不可能三角”又随之而来:追求顶级、高速的智能(如GPT-4o/Claude 3.5),就必须接受高昂的调用成本;追求低成本,又往往要在性能和稳定性上做出妥协。开发者“既要又要”的正义,谁能给?
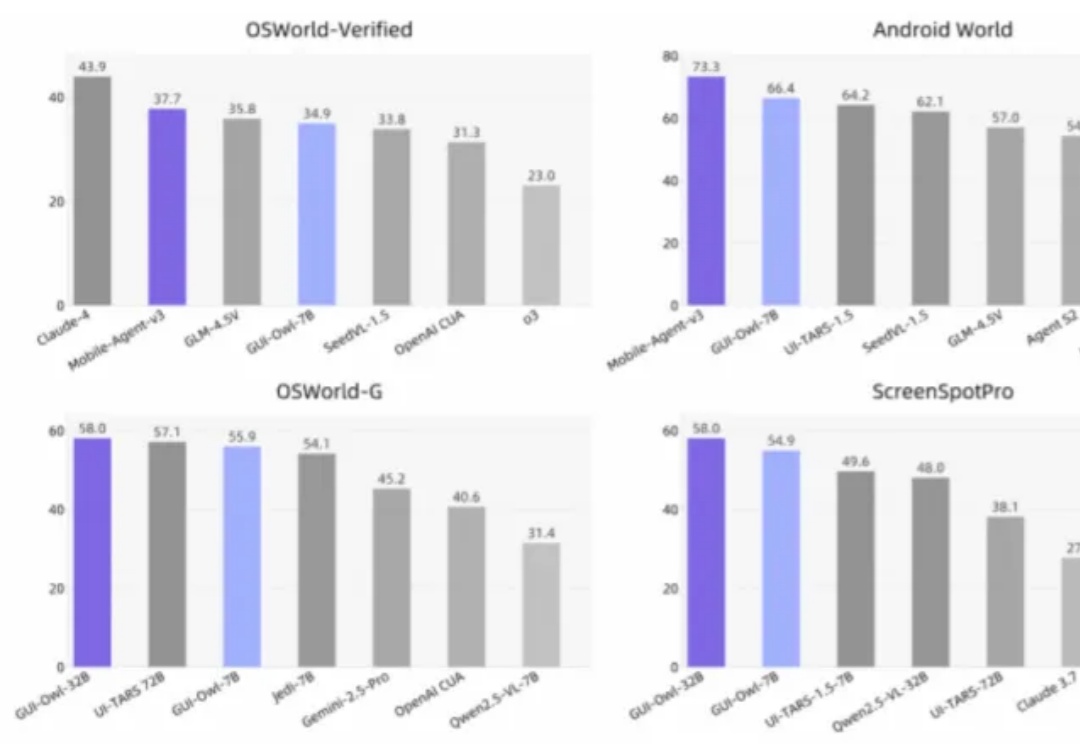
覆盖桌面、移动和 Web,7B 模型超越同类开源选手,32B 模型挑战 GPT-4o 与 Claude 3.7,通义实验室全新 Mobile-Agent-v3 现已开源。

小时候完成月考测试后,老师会通过讲解考试卷中吃错题让同学们在未来取得好成绩。